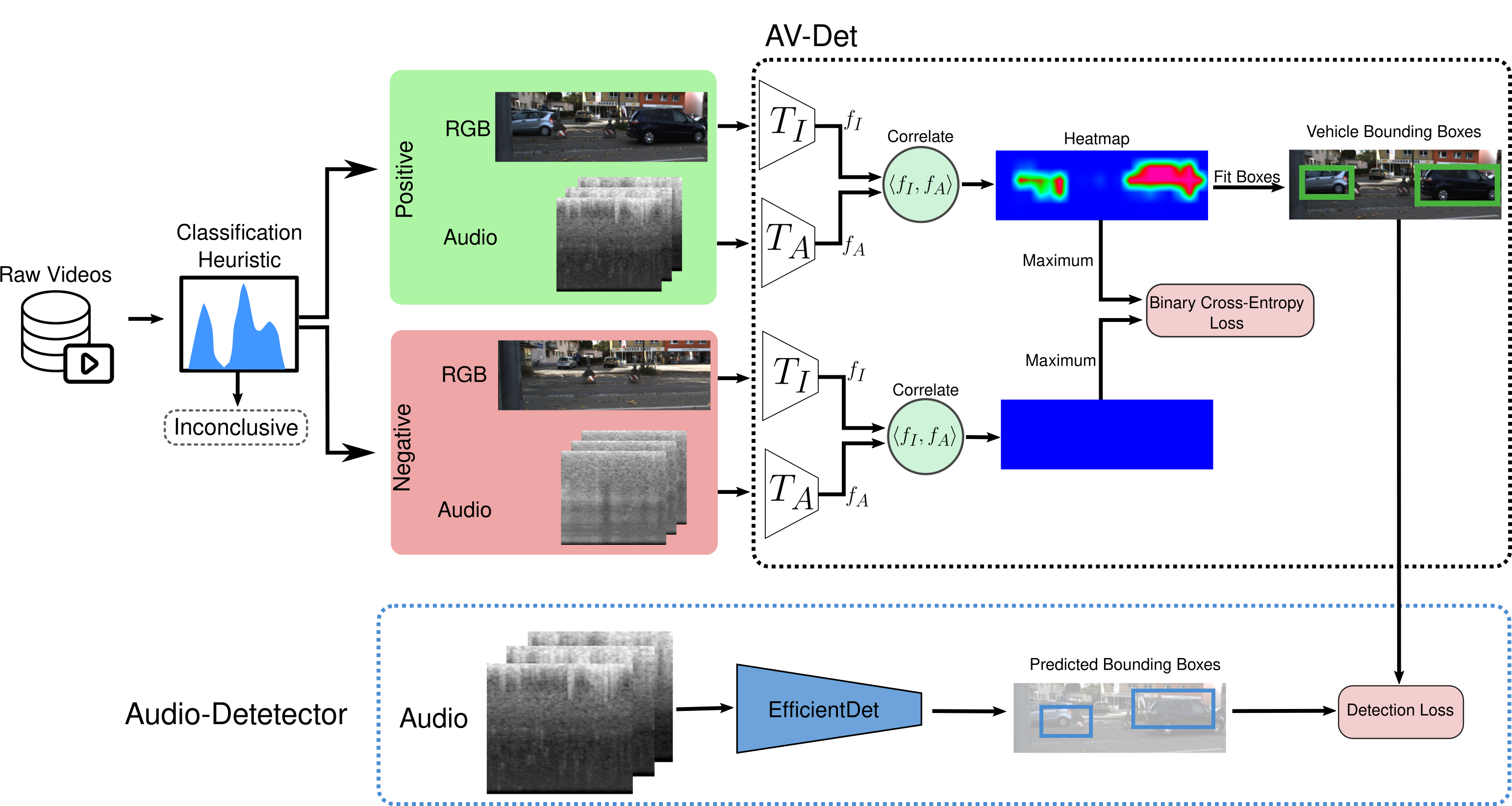
Technical Approach
Robust detection of moving vehicles is a critical task for any autonomously operating outdoor robot or self-driving vehicle. Most modern approaches for solving this task rely on training image-based detectors using large-scale vehicle detection datasets such as nuScenes or the Waymo Open Dataset. Providing manual annotations is an expensive and laborious exercise that does not scale well in practice. To tackle this problem, we propose a self-supervised approach that leverages audio-visual cues to detect moving vehicles in videos. Our approach employs contrastive learning for localizing vehicles in images from corresponding pairs of images and recorded audio. In extensive experiments carried out with a real-world dataset, we demonstrate that our approach provides accurate detections of moving vehicles and does not require manual annotations. We furthermore show that our model can be used as a teacher to supervise an audio-only detection model. This student model is invariant to illumination changes and thus effectively bridges the domain gap inherent to models leveraging exclusively vision as the predominant modality.